
It’s the last day of the month. The stall is quiet between rounds. Vijay has two notebooks on the counter — last month and this month — and a small calculator. Last month’s mean: 87 customers per day. This month’s mean: 91.
Last month he sold tea, biscuits-from-the-tin, and cigarettes. This month, halfway through, he started serving fresh ginger biscuits baked in the back, by his cousin’s wife who started a small bakery. Same tea. Same hours. Same prices. Just the new biscuits.
He stares at the gap. Four customers more, on average. Is that the biscuits doing their work? Or is it just the kind of wobble he sees from one month to the next anyway?
He has read enough now to know he wants a test. He has read about t-tests and p-values and Type I errors. But before he can run anything, he realises he has not figured out the most basic thing: what claim am I testing against what?
He mutters, “Same data, two stories. Which one is the default?”
The awning rustles.
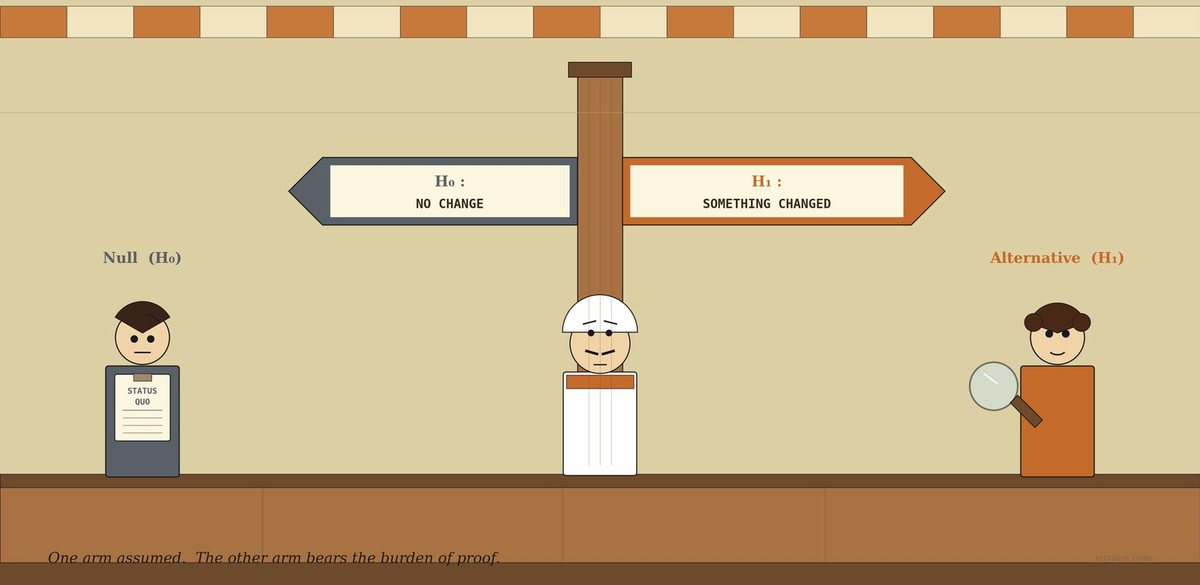
A man walks in first — calm, deliberate, plain grey kurta, slightly stooped. He carries a small clipboard. The clipboard has the words STATUS QUO written across the top in neat capitals. A few horizontal lines below, none of them filled in. He sets the clipboard on the counter, folds his arms, and waits.
A second man comes in behind him — bright orange shirt, curly hair, a small brass-rimmed magnifying glass in his right hand. He is already peering at Vijay’s notebook before he has even said hello. He flips a page. Squints.
The first man speaks first. “I am the Null hypothesis. People write me as H₀. I am the boring default. I am what the world was before you started fiddling with it. My claim is simple: nothing changed. Your new biscuits did nothing. The four-customer gap is sampling noise.”
The second man does not look up from the notebook. “I am the Alternative hypothesis. People write me as H₁ — sometimes Hₐ. I am what you actually want to find evidence for. My claim is: something did change. The biscuits helped. The four-customer gap is real.”
Vijay says, “But I came here to find out whether the biscuits helped. So why is the boring one — the one who says nothing happened — the default?”
They reply, together, “Because that’s the only fair starting point.”
Null speaks first
Null sets his clipboard squarely. He says, “Imagine I am the defendant in a courtroom. The prosecution — that gentleman with the magnifying glass — says I am guilty of having no effect.”
He pauses for effect. “But our system, the one that statistics borrowed from law, says: I am presumed innocent. The data has to prove me guilty. Not me prove myself innocent. I do nothing. I sit. I assume my own truth. The burden is on the prosecution.”
Vijay looks at him. “So the burden is on the biscuits-helped claim. Not on the biscuits-did-nothing claim.”
“Exactly. The data has to be strong enough to convict me. If it isn’t, I walk free. Not because I have proven my innocence — but because the prosecution couldn’t prove their case. There is a deep asymmetry here. You can reject me. You can never prove me. All you can ever do is fail to reject me.”
Vijay frowns. “That sounds like a technicality.”
“It is the most important sentence in hypothesis testing. Most people get it wrong, including textbooks. You do not ‘accept the null’. You only ever ‘fail to reject the null’. Like an acquittal — which says not guilty, never innocent.”
Alternative speaks
Alternative finally looks up from the notebook. He flips it shut. He says, “Now me. I am the interesting claim. I am what you want to be true. I am the new biscuits, the redesigned menu, the cousin’s marketing idea, the new variety of leaves. I am whatever the change was.”
He waves the magnifying glass. “But I cannot just walk in and say I am true. The court will throw me out. I have to bring evidence. Specifically: data so unlikely-under-the-null that the null becomes implausible enough to reject.”
Vijay says, “So I need to show that a four-customer gap is bigger than what I would expect if my biscuits did nothing. That’s the test.”
“That’s the test. I, the Alternative, am the direction of your effect. There are different flavours of me, depending on what you want to claim:
- the biscuits helped —
H₁: μ > μ₀— a one-sided alternative, on the higher side - the biscuits hurt —
H₁: μ < μ₀— a one-sided alternative, on the lower side - the biscuits changed something — up or down, I don’t know which —
H₁: μ ≠ μ₀— a two-sided alternative
You pick which one of me you’re claiming. Before you look at the data. Not after.”
Vijay says, “Why before?”
Alternative smiles. “Because if you peek first and then write your alternative to match what you saw, you cheat. The whole machinery breaks. Decide first. Run the test. Live with the answer.”
What just happened
Vijay sits down on his counter. He looks at his two characters. He looks at his two notebooks. He starts to write the framing of his test on the inside cover of the new notebook.
H₀: μ = 87. The new biscuits did nothing. This month’s customer flow is the same as last month’s.
H₁: μ > 87. The new biscuits helped. Customers went up.
He shows the page to Null. Null nods approvingly.
He shows it to Alternative. Alternative says, “Good. One-sided, in the direction you actually believe in. Now run your t-test against this null. If p < 0.05, you reject the null. If not, you fail to reject. Either way, you write down the verdict, you don’t lie about it, and you don’t move the goalposts.”
Vijay says, slowly, getting it now, “And the direction is encoded in the alternative, not the null.”
Both nod.
“The null is always the equality. No effect. No change. No difference. It is the world before the thing I am testing.”
“The alternative is the interesting claim. Something happened. It is the world after the thing I am testing — if my theory is right.”
The same chat, in a chart

That picture is exactly the same conversation, drawn. The first panel is the side-by-side: Null and Alternative as two columns, with the same three rows answered for each — what they claim, who bears the burden, what the verdict means. The second panel is the courtroom mechanic, drawn as a scale: H₀ sits on the left pan (empty by default), H₁ sits on the right pan, and the test is whether the data piles enough weight on the H₁ pan to tip the scale. If it doesn’t tip, H₀ wins by sitting still. The third panel is the two of them in person — clipboard and magnifying glass.
One last warning before they leave
Null packs his clipboard back under his arm. He says, “Three traps people fall into.”
He counts them off.
“One. Don’t say ‘I accept the null.’ You only ever fail to reject me. Saying you ‘accept’ me is claiming evidence for me — there isn’t any. Absence of evidence is not evidence of absence.”
“Two. The null isn’t always an equality. The classic form is H₀: μ = μ₀, but for one-sided tests it’s often written H₀: μ ≤ μ₀ (when you want to claim strictly greater). The = form is just the boundary case — the hardest version of the null to reject — so most software defaults to it. If you’re claiming greater than, the null spans less than or equal to, and the test is the same.”
“Three. Don’t move the alternative after looking at the data. If you originally said H₁: μ > 87, ran the test, saw the data went down instead of up, and switched to H₁: μ < 87, you have committed a small statistical sin called HARKing — Hypothesising After the Results are Known. Your p-value is now meaningless. You can’t peek, then re-aim, then claim significance. Decide direction. Run test. Live with answer.”
Alternative tucks his magnifying glass into his pocket. “And one more from me. The meaningful hypothesis is not what your software gives you by default. Your spreadsheet’s t.test() defaults to a two-sided alternative — μ ≠ μ₀. If your real claim is one-sided — the biscuits helped — you have to tell the software. The two-sided test wastes half your statistical power on a direction you don’t care about.”
Vijay nods. “So I should run the test as one-sided, since I genuinely care about up and not down.”
“Yes. As long as you decided that before you looked at this month’s mean.”
Quick gut-check
Three real-world scenarios. State the null and alternative for each.
- A pharma company is testing a new pain-relief tablet. They want to claim it reduces pain more than the existing tablet.
- A coin is being checked for fairness — by the regulator, with no prior reason to suspect either side.
- A teacher claims her new teaching method improves test scores. The school will only adopt it if the improvement is big enough.
Scenario 1. H₀: μ_new = μ_existing (the new tablet works no better than the existing one). H₁: μ_new < μ_existing (the new tablet reduces pain more — a one-sided alternative on the lower-pain side, since “more relief” means lower pain scores). The pharma company bears the burden of proof. Scenario 2. H₀: p = 0.5 (the coin is fair). H₁: p ≠ 0.5 (the coin is unfair — could be biased either way, two-sided alternative). The regulator bears the burden of proving unfairness. Scenario 3. H₀: μ_new = μ_old (the method makes no difference). H₁: μ_new > μ_old (the method improves scores — one-sided). The teacher bears the burden of proof.
The pattern in all three: the null is the equality, the boring default. The alternative is the interesting claim, with a direction (one-sided) or without (two-sided) depending on what you actually want to argue.
The bill
Vijay closed the new notebook. He had framed his test. H₀: μ = 87. H₁: μ > 87. One-sided. He would run the t-test next. If the data tipped the scale, he would reject the null and conclude — cautiously, in the language of the courtroom — that the evidence supports the biscuits-helped claim. If it didn’t tip, he would not say the biscuits did nothing. He would say he failed to reject the null. And he would think more carefully about whether the test was strong enough to detect the kind of effect he cared about — which is the Type II / power conversation from another afternoon.
Null tucked his clipboard under his arm and walked out, calm as ever. Alternative pocketed his magnifying glass, finished his tea in one swallow, and left a tip larger than warranted, as if to celebrate the very idea that anything might change. The fan ticked. The kettle hissed. Vijay turned to a fresh page and wrote the only sentence he wanted to remember from the visit:
The null is the world before. The alternative is the claim I’m making. The data either tips the scale, or it doesn’t. I never say “accept” — only “reject” or “fail to reject.”
For the math-curious
Standard form: –
H₀: μ = μ₀(or≤,≥for one-sided variants) –H₁: μ ≠ μ₀(two-sided) orH₁: μ > μ₀(one-sided, upper) orH₁: μ < μ₀(one-sided, lower)Why “fail to reject”? The framework you’re using was set up by Jerzy Neyman and Egon Pearson in
1933. They built it as a decision procedure: at significance level α, you either reject H₀ or you don’t, full stop. The verdict “do not reject” is not the same as “H₀ is true”. It is “the evidence wasn’t strong enough to convict”. Karl Popper’s later philosophy of science amplified the same point — you can falsify a theory but never prove it.One-sided vs two-sided power: a one-sided test is more powerful (lower β, higher chance of rejecting H₀ when H₁ is true) if you correctly guess the direction. If you guess wrong, you have no chance of rejecting in the right direction. The two-sided test is the safer default when you genuinely don’t know which way an effect would go.
Same data. Two framings. The default is always the boring one — and the interesting one bears the burden of proof.