
It’s a Wednesday afternoon. The fan turns slowly. The kettle is on. Vijay has framed his hypothesis (H₀: μ = 3.8, H₁: μ ≠ 3.8) and is sitting at the counter with the calculator open. He is about to test whether the pinch of cardamom he started adding to his tea this month has changed customer satisfaction.
Last month’s mean rating: 3.8 stars. This month’s: 4.0. He has thirty days of ratings on each side.
He types in the t-test command. The calculator pauses and asks him a question he has never thought about before:
One-sided or two-sided?
He stares at it. He has no idea.
He mutters, “Same data. Same hypothesis. Why does the calculator care which side?”
The awning rustles.
A man walks in first — focused, deliberate, warm orange shirt, eyes already narrowed on something in the distance. He holds a single arrow in his right hand, pointing it like a pointer toward the back wall. He places himself squarely on the left side of the counter.
A second man comes in behind him — calm, even-handed, teal shirt, slight smile. He holds two arrows, one in each hand, pointing in opposite directions. He looks like a Janus figure or a referee. He places himself on the right side.
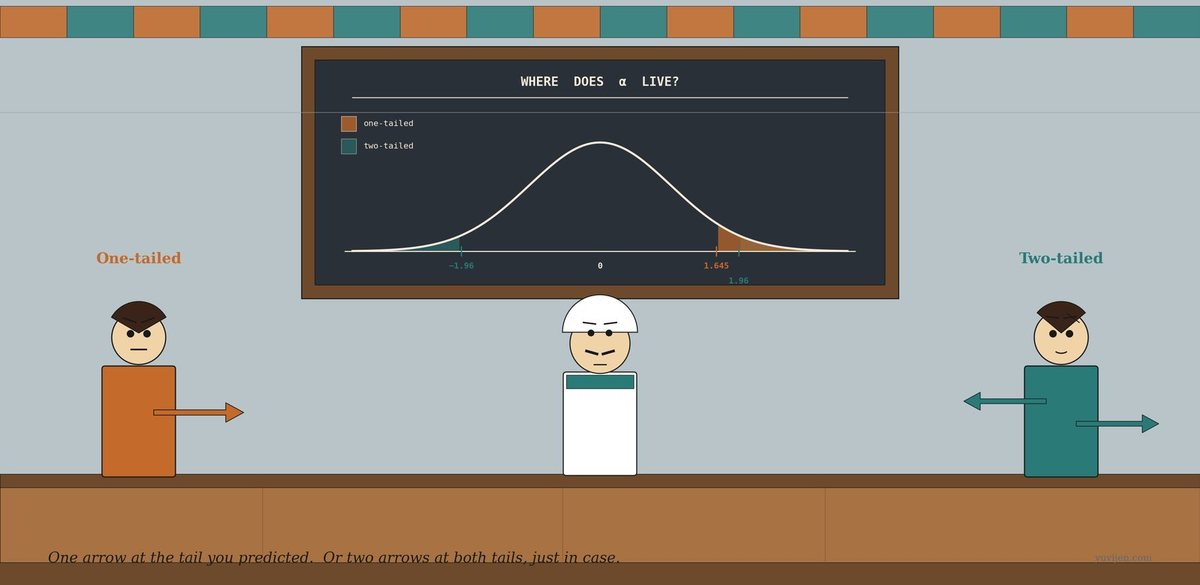
The first man speaks. “I am the one-tailed test. I assume you know which way your effect should go. You believe the cardamom helps? Then I put all five percent of my α on the right tail of the curve. I am sharper there. I am also useless if your effect goes the other way.”
The second man says, “I am the two-tailed test. I do not assume direction. I split α in half — two-and-a-half percent on each tail. I will reject if the data is far enough out either side. I am safer. I am also blunter — I need a bigger effect to reject than my brother does.”
Vijay says, “Same α. But you put it in different places.”
Both nod. “Exactly.”
One-tailed speaks first
One-tailed unfurls his arrow and lays it on the counter. He says, “Look. Your hypothesis is H₁: μ > 3.8. You are claiming the cardamom helped. You don’t care if it hurt. You wouldn’t even run the test if it hurt — you would just stop adding it.”
He continues, “If I put all my α on the right side — say the critical z-value is 1.645 for α = 0.05 — then I will reject the null whenever your test statistic is greater than 1.645. I am tuned to the side you actually care about.”
Vijay says, “And the bigger your z, the smaller the p-value. So a one-tailed test with the correct direction gives me a smaller p-value than a two-tailed test for the same data.”
“Yes. About half the p-value, in fact, when the direction is right. One-tailed is more powerful in that case — better at catching real effects. That’s the upside.”
He pauses. “But here’s the downside. If the cardamom actually hurts satisfaction — if the test statistic comes back at −2.5, hugely significant on the wrong side — I would still fail to reject. I am not looking at the left tail. I have my back turned. I will report ‘no significant change’ even though the data is screaming about a huge negative effect.”
Vijay’s eyes widen. “So I have to be sure about my direction before I commit to you.”
“Sure enough that you would treat a strong opposite effect as ‘no result’ rather than a finding. That’s the bargain. Direction commitment in exchange for sharpness.”
Two-tailed speaks
Two-tailed picks up his two arrows and waves them gently, one each side. He says, “I am what your software gives you by default. And honestly, for most exploratory questions, I am the right call.”
He continues, “I split α into two halves. For α = 0.05, I put 0.025 on each tail. That makes my critical z-values ±1.96. To reject the null, your test statistic has to be more extreme than 1.96 or less than −1.96. Either side works.”
Vijay says, “So the bar is higher for me to reject?”
“Yes. The bar is at 1.96 instead of 1.645. To get the same level of significance with me, your data has to be that much further from the null. I am more conservative.”
He sets the arrows down. “But I cover you. If the cardamom actually hurt and your z-statistic came back at −2.5, I would catch that. I am watching both tails.”
He smiles. “And there is a deep reason most journals and most software default to me. I am the safer choice when you do not have a priori, theoretically grounded reason to expect a specific direction. Most effects in real life could go either way. Most theories aren’t ironclad about direction. So unless you have a strong, pre-registered, defensible reason to commit to one direction — I am the honest answer.”
What just happened
Vijay sits down with both characters in front of him and runs the trade-off through his head.
He says, slowly, “If I genuinely know the direction — really know, with theory and prior data behind me — one-tailed is more powerful. Smaller p-value, easier to reject, better at catching small real effects. In that direction.”
Both nod.
“If I’m not sure of direction — or my honesty requires me to admit I’d have run the test even if the effect went the other way — two-tailed is the safer call. Bigger threshold, but it covers both sides.”
Both nod again.
One-tailed adds, “And there’s one ethical line. Pick before you look at the data. If you peek at the data, see it’s just barely insignificant in a two-tailed test, and then ‘realise’ you actually meant to run a one-tailed test all along — you have committed a small statistical sin. The community calls this p-hacking in one of its mildest forms. Don’t do it.”
Two-tailed says, “And the related sin: halving the two-sided p-value to claim one-sided significance. If your software gave you p = 0.08 two-sided, and you write p = 0.04 one-sided to get under the magic 0.05 line — same crime. The decision had to be made before you knew which direction the data fell.”
Vijay nods. “Decide direction. Run test. Report honestly.”
The same chat, in a chart

That picture is exactly the same conversation, drawn. The first panel is the one-tailed geometry — all five percent of α concentrated on the right tail, critical value at 1.645. The second panel is the two-tailed geometry — α split into two halves of 0.025 each, critical values at ±1.96. Notice how the two-tailed test’s threshold is further out on the right side than the one-tailed test’s: 1.96 vs 1.645. That’s the cost of agnostic direction. The third panel shows the two strangers in person, in case you forget which arrow goes with which.
One last warning before they leave
One-tailed packs his arrow under his arm. Two-tailed tucks his pair into a little quiver. They look at Vijay together.
One-tailed says, “Three traps.”
He counts them off.
“One. Don’t pick one-tailed just to get a smaller p-value. The choice has to be defensible before the data. If a reviewer asks ‘why one-tailed?’ and your answer is ‘because two-tailed wasn’t significant’, you have lost the argument.”
“Two. The ‘obvious direction’ trap. Sometimes effects go the way you don’t expect. The new pain medication makes things worse. The redesigned website confuses users. The cardamom annoys regulars. If your one-tailed test is pointing at the right tail and the truth is on the left tail, you will report ‘no effect’ and walk away from a real finding — possibly an important one.”
“Three. Equivalence isn’t directionality. Some questions are genuinely two-sided: is this coin fair? is this drug equivalent to placebo? did the algorithm change customer behaviour? For these, two-tailed isn’t a default — it’s the correct form of the question.”
Two-tailed adds, “And one defence of one-tailed in actual practice: when the cost of being wrong on one side is dramatically asymmetric. A new generic drug only matters if it’s not worse than the brand-name. You genuinely don’t care if the new drug is much better — you’re testing for non-inferiority, which is one-tailed by design. That’s a legitimate use. So is one-tailed in safety testing — is the new car safer than the old one? Direction is built into the question.”
Vijay nods. “So most of the time, two-tailed. One-tailed only when the question genuinely has a single direction baked in — and that direction was committed to before the data.”
Both confirm. “Yes.”
Quick gut-check
Three real scenarios. One-tailed or two-tailed?
- A pharma company wants to claim a new pill reduces blood pressure more than placebo. They want to ship the result to the FDA.
- A teacher is checking whether her two classes — morning and evening — have different average exam scores.
- A factory tests whether a new bolt has the same breaking strength as the old bolt. The new bolt will replace the old one only if it is at least as strong.
Scenario 1. One-tailed. The pharma company only cares about the new pill being better (lower blood pressure). If it’s worse, they won’t ship. The direction is locked in before the trial. H₀: μ_new ≥ μ_placebo, H₁: μ_new < μ_placebo. Scenario 2. Two-tailed. The teacher has no a priori reason to think one class is better than the other; she’s just checking for a difference. Either direction is interesting. H₀: μ_morning = μ_evening, H₁: μ_morning ≠ μ_evening. Scenario 3. One-tailed (non-inferiority). The factory only cares about the new bolt being not weaker. If it’s stronger, that’s fine but irrelevant to the decision. The decision is “as strong or stronger” vs “weaker”, which is one-sided. H₀: μ_new ≥ μ_old, H₁: μ_new < μ_old.
In all three, the test framing matches the decision you would make based on the result. If the decision is symmetric (you’d react the same way to both directions), use two-tailed. If the decision is asymmetric (you only care about one direction), use one-tailed.
The bill
Vijay closed the calculator without running the test yet. He realised his cardamom question was actually two-tailed — he had assumed it would help, but he wasn’t sure. Customers might find it overpowering. He had no theoretical, pre-data reason to lock in a direction. The honest framing was:
H₀: μ = 3.8. H₁: μ ≠ 3.8. Two-tailed. α = 0.05. Critical values: ±1.96.
He ran the test. (We will not tell you the result. The post is about the choice, not the answer.)
One-tailed walked out, his single arrow tucked under his arm, posture sharp. Two-tailed followed, his two arrows balanced one in each hand, walking like a man who weighed both sides of every conversation. The fan ticked. The kettle hissed. Vijay turned to a fresh page and wrote, in the margin:
Same α. Different geometry. One-tailed if the question has a built-in direction. Two-tailed otherwise. Decide before you look — never after.
For the math-curious
Critical values for α = 0.05 (standard normal): – One-tailed:
z = 1.645(right side) orz = −1.645(left side, depending on H₁) – Two-tailed:z = ±1.96The p-value relationship: – One-tailed (right):
p = P(Z ≥ z_obs)– One-tailed (left):p = P(Z ≤ z_obs)– Two-tailed:p = 2 × min(P(Z ≥ |z_obs|), P(Z ≤ −|z_obs|))= 2 × the one-tailed p, when the direction is rightPower asymmetry: A one-tailed test has more power than a two-tailed test at the same α — if the true effect is in the predicted direction. If the true effect is in the opposite direction, the one-tailed test has effectively zero power to detect it.
Most-common defaults: most statistical software (R’s
t.test(), Python’sscipy.stats.ttest_*, Excel’sT.TEST) uses two-tailed by default. To run a one-tailed test you have to explicitly setalternative = "greater"or"less". The default is the safer choice for a reason.
Same data. Same α. Different question — and a different threshold to clear.